Hướng Dẫn Sử Dụng SenseVoice Model: Nhận Diện Giọng Nói Và Phân Tích Cảm Xúc

Giới Thiệu SenseVoice
SenseVoice là một mô hình nền tảng AI mạnh mẽ dành cho các ứng dụng xử lý giọng nói, bao gồm:
- Nhận diện giọng nói tự động (ASR)
- Phân biệt ngôn ngữ nói (LID)
- Nhận diện cảm xúc qua giọng nói (SER)
- Phát hiện sự kiện âm thanh (AED)
Mô hình này được thiết kế để hỗ trợ nhiều ngôn ngữ, nhận diện cảm xúc chính xác và phát hiện sự kiện âm thanh nhanh chóng.
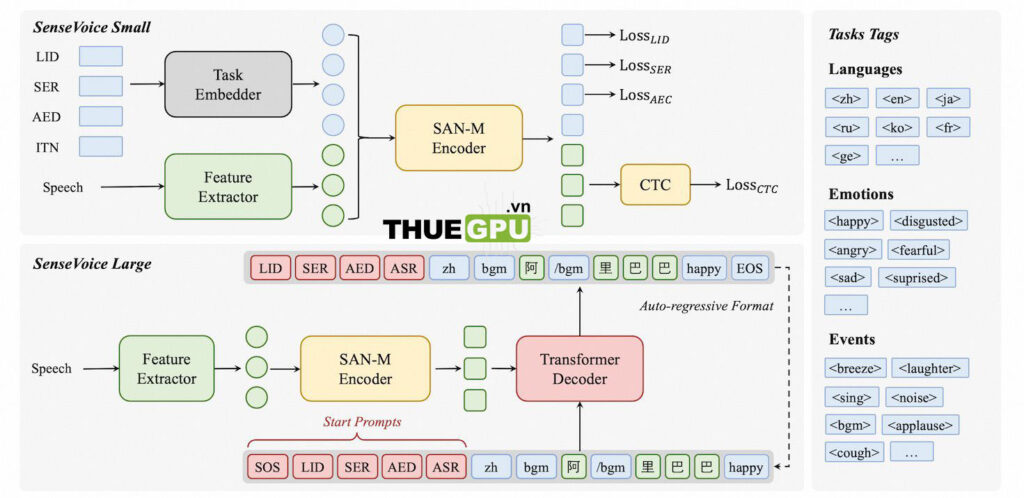
Các Điểm Nổi Bật Của SenseVoice
- Nhận Diện Giọng Nói Đa Ngôn Ngữ:
- Được huấn luyện với hơn 400.000 giờ dữ liệu.
- Hỗ trợ hơn 50 ngôn ngữ với độ chính xác cao hơn Whisper.
- Hiệu Quả Suy Luận:
- Mô hình SenseVoice-Small xử lý 10 giây âm thanh chỉ trong 70ms, nhanh gấp 15 lần so với Whisper-Large.
- Nhận Diện Cảm Xúc Và Sự Kiện:
- Nhận diện các sự kiện phổ biến như tiếng vỗ tay, tiếng cười, tiếng khóc, ho, và hắt hơi.
- Tiện Lợi Khi Tùy Chỉnh:
- Hỗ trợ kịch bản tinh chỉnh dễ dàng để đáp ứng các nhu cầu kinh doanh cụ thể.
- Triển Khai Dịch Vụ:
- Tích hợp dễ dàng với các ngôn ngữ lập trình như Python, C++, HTML, Java và C#.
- Hỗ trợ xử lý nhiều yêu cầu đồng thời.
Hướng Dẫn Cài Đặt SenseVoice
Bước 1: Tải Về Dự Án Và Tạo Môi Trường Python 3.8+
- Clone dự án từ GitHub:

- Tạo và kích hoạt môi trường Python:



Bước 2: Cài Đặt Các Phụ Thuộc
- Cài đặt các gói cần thiết:

Bước 3: Khởi Chạy Giao Diện WebUI
- Tải mô hình (thời gian tải sẽ lâu do kích thước lớn).
- Khởi chạy WebUI:

- Truy cập giao diện WebUI tại địa chỉ
http://<IP mạng LAN>:7860.

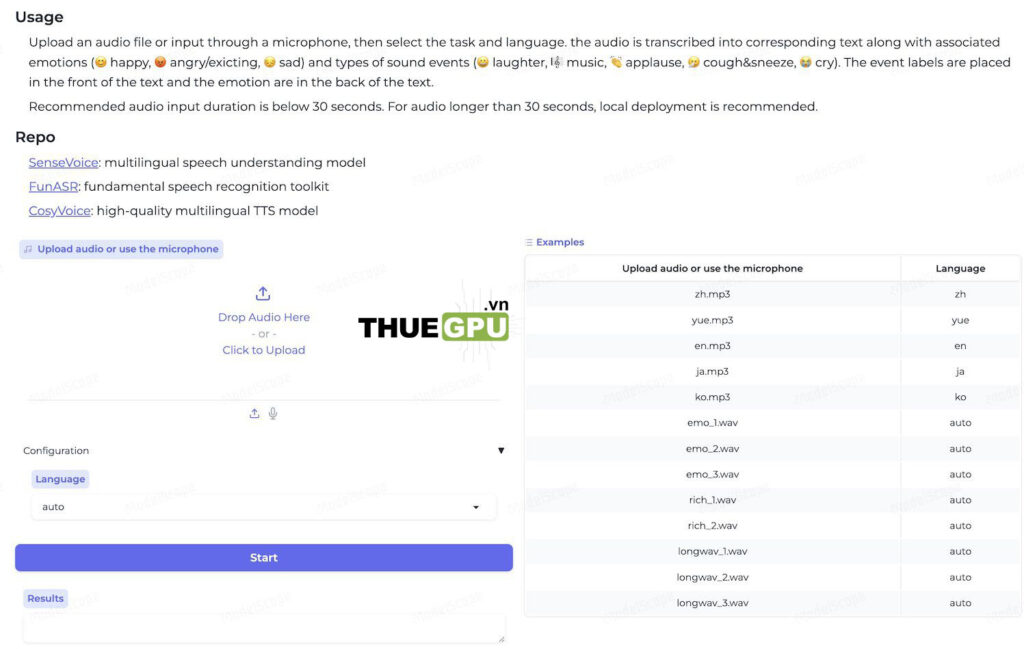
Hướng Dẫn Sử Dụng SenseVoice
Phương Pháp 1: Sử Dụng Web UI
- Truy cập giao diện WebUI.
- Tải tệp âm thanh cần phân tích.
- Chọn ngôn ngữ (nếu cần).
- Nhấn “Start” và chờ quá trình xử lý hoàn tất. Kết quả sẽ hiển thị ở khu vực Results.
Ví dụ hiệu suất:
Với GPU NVIDIA RTX A4000, xử lý 90 phút âm thanh chỉ mất khoảng 8 phút.
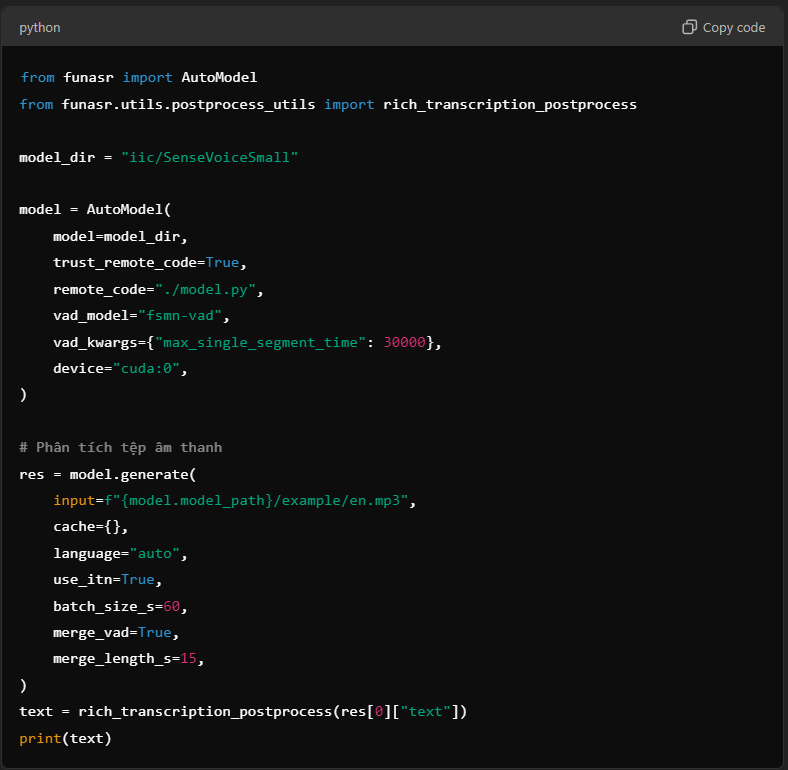
Phương Pháp 2: Lập Trình Python
Mẫu Sử Dụng Cơ Bản
Sử dụng Python để gọi mô hình và phân tích tệp âm thanh:
Xuất Mô Hình Sang ONNX Hoặc Libtorch
Xuất mô hình sang định dạng Libtorch:

Lời Khuyên Tối Ưu
- Sử Dụng GPU: Các GPU như NVIDIA RTX A4000 đảm bảo tốc độ xử lý tối ưu.
- Tùy Chỉnh Theo Nhu Cầu: Sử dụng các script tinh chỉnh để phù hợp với lĩnh vực cụ thể.
- Tích Hợp API: Tận dụng API của SenseVoice để phát triển ứng dụng tùy chỉnh.
- Đồng Bộ Nhiều Yêu Cầu: Cấu hình pipeline để hỗ trợ đồng thời nhiều yêu cầu.
Kết Luận
SenseVoice là một công cụ mạnh mẽ, hỗ trợ nhận diện giọng nói đa ngôn ngữ, phân tích cảm xúc, và phát hiện sự kiện âm thanh. Với giao diện WebUI thân thiện và khả năng tùy chỉnh qua Python, SenseVoice phù hợp với nhiều lĩnh vực ứng dụng từ AI, chăm sóc khách hàng, đến các giải pháp thông minh cho doanh nghiệp.
Hãy bắt đầu khám phá sức mạnh của SenseVoice cho dự án của bạn ngay hôm nay!
Hãy tiếp tục xem thêm các bài viết khác của chúng tôi tại ThueGPU.vn hoặc Fanpage. Nếu có nhu cầu Thuê máy chủ GPU, CLOUD GPU hãy liên hệ với chúng tôi.
CÔNG TY TNHH CÔNG NGHỆ EZ
- VP HCM: 211 Đường số 5, Lake View City, An Phú, Thủ Đức.
- Tel: 0877223579
- Email: [email protected]








